TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning
Shiming Chen1, Ziming Hong1, Wenjin Hou1, Guo-Sen Xie2, Yibing Song3, Jian Zhao4, Xinge You1,
1Huazhong University of Science and Technology (HUST), China 2Nanjing University of Science and Technology, China
3 AI Institute, Fundan University, China 4Institute of North Electronic Equipment, China
5Sea AI Lab (SAIL), Singapore 6 Terminus Group
{shimingchen, youxg}@hust.edu.cn {hoongzm, gsxiehm}@gmail.com zhaojian90@u.nus.edu shuicheng.yan@gmail.com ling.shao@ieee.org
Abstract
Zero-shot learning (ZSL) tackles the novel class recognition problem by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is typically represented by attribute descriptions shared between different classes, {\color{blue}which act as strong priors for localizing object attributes that represent discriminative region features,} enabling significant and sufficient visual-semantic interaction for advancing ZSL. Existing attention-based models have struggled to learn inferior region features in a single image by solely using unidirectional attention, {\color{blue}which ignore the transferable and discriminative attribute localization of visual features for representing the key semantic knowledge for effective knowledge transfer in ZSL.} In this paper, we propose a cross attribute-guided Transformer network, termed TransZero++, to refine visual features and learn accurate attribute localization for key semantic knowledge representations in ZSL. Specifically, TransZero++ employs an attribute$\rightarrow$visual Transformer sub-net (AVT) and a visual$\rightarrow$attribute Transformer sub-net (VAT) to learn attribute-based visual features and visual-based attribute features, respectively. By further introducing feature-level and prediction-level semantical collaborative losses, the two attribute-guided transformers teach each other to learn semantic-augmented visual embeddings for key semantic knowledge representations via semantical collaborative learning. Finally, the semantic-augmented visual embeddings learned by AVT and VAT are fused to conduct desirable visual-semantic interaction cooperated with class semantic vectors for ZSL classification. Extensive experiments show that TransZero++ achieves the new state-of-the-art results on three golden and challenging ZSL benchmarks. The project website is at: \url{https://shiming-chen.github.io/TransZero-pp/TransZero-pp.html}.
Model pipeline
Figure:The architecture of the proposed TransZero++ model. TransZero++ consists of an attribute$\rightarrow$visual Transformer sub-net (AVT) and a visual$\rightarrow$attribute Transformer sub-net (VAT). AVT includes a feature augmentation encoder that alleviates the cross-dataset bias between ImageNet and ZSL benchmarks and reduces the entangled geometry relationships between different regions for improving the transferability of visual features, and an attribute$\rightarrow$visual decoder that localizes object attributes for attribute-based visual feature representations based on the semantic attribute information. Analogously, VAT learns visual-based attribute features using the similar feature augmentation encoder and a visual$\rightarrow$attribute decoder. Finally, two mapping functions $\mathcal{M}_1$ and $\mathcal{M}_2$ map the learned attribute-based visual features and visual-based attribute features into semantic embedding space respectively under the guidance of semantical collaborative learning, enabling desirable visual-semantic interaction for ZSL classification.
Material
Evaluation
There are three popular challenging benchmark datasets used for evaluating our method: CUB, SUN, and AWA2. Some sampls are presented below.
We conduct experiments both in Conventional Zero-Shot Learning (CZSL) and Generalized Zero-Shot Learning (GZSL) settings. In the CZSL setting, we predict the unseen classes to compute the accuracy of test samples, i.e., ACC. In the GZSL setting, we calculate the accuracy of the test samples from both the seen classes (denoted as S) and unseen classes (denoted as U), and their harmonic mean H.

Experiment 1: Comparison with State-of-the-Art
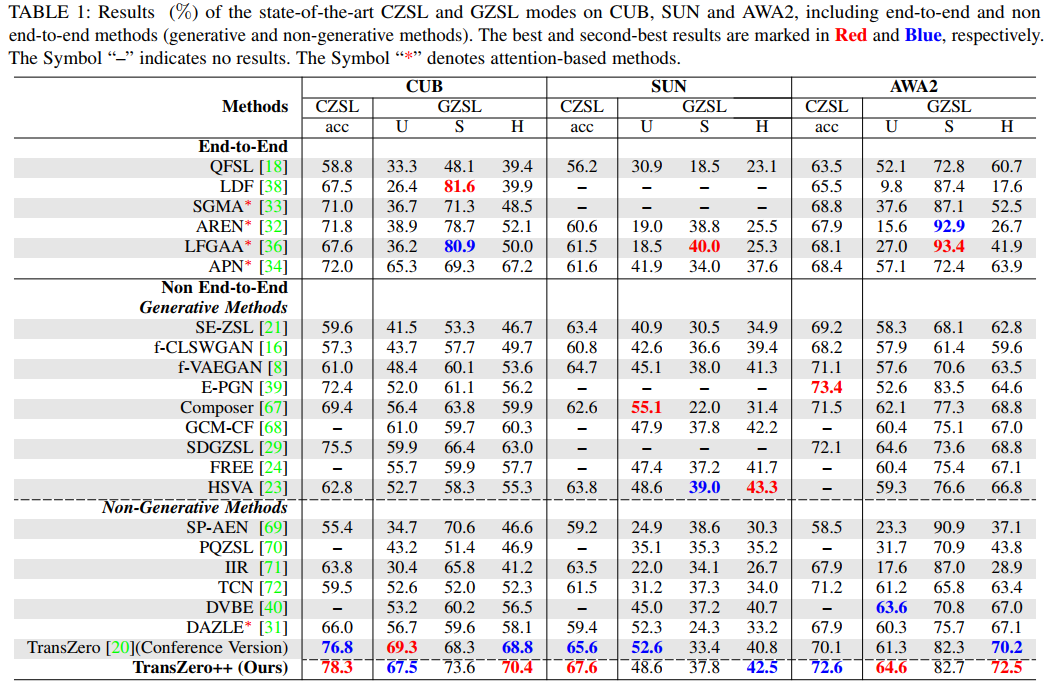
Experiment 2: Ablation Study
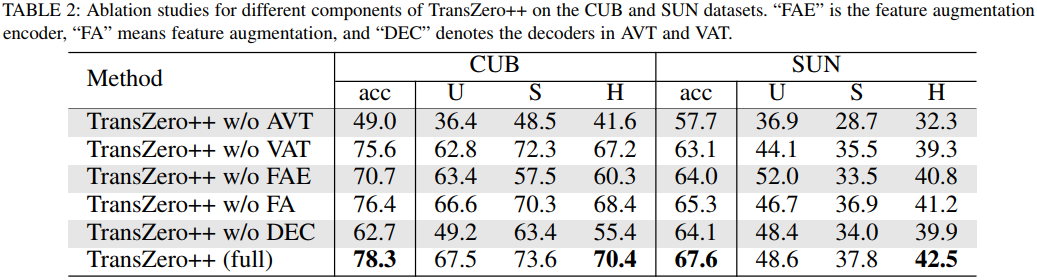
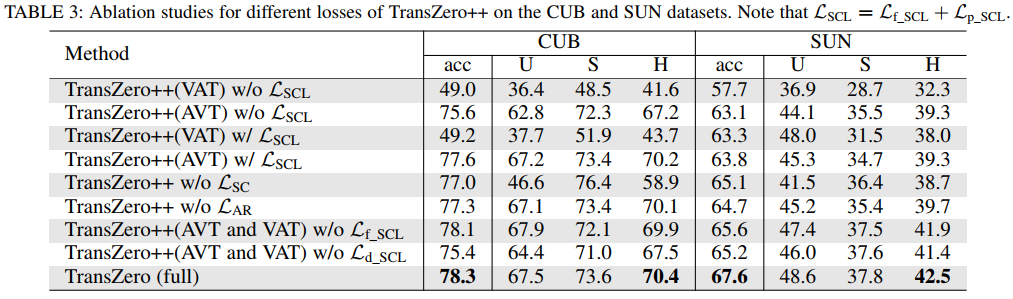
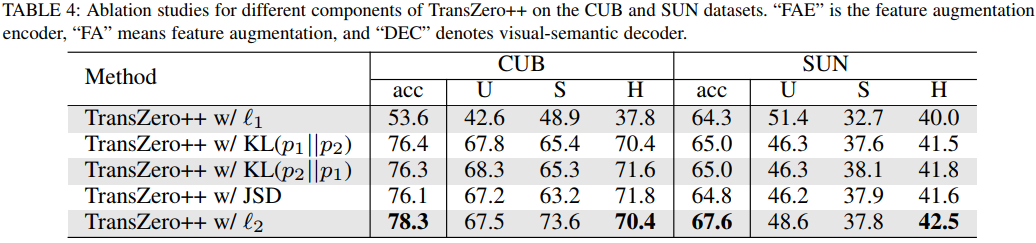
Experiment 3: t-SNE Visualization
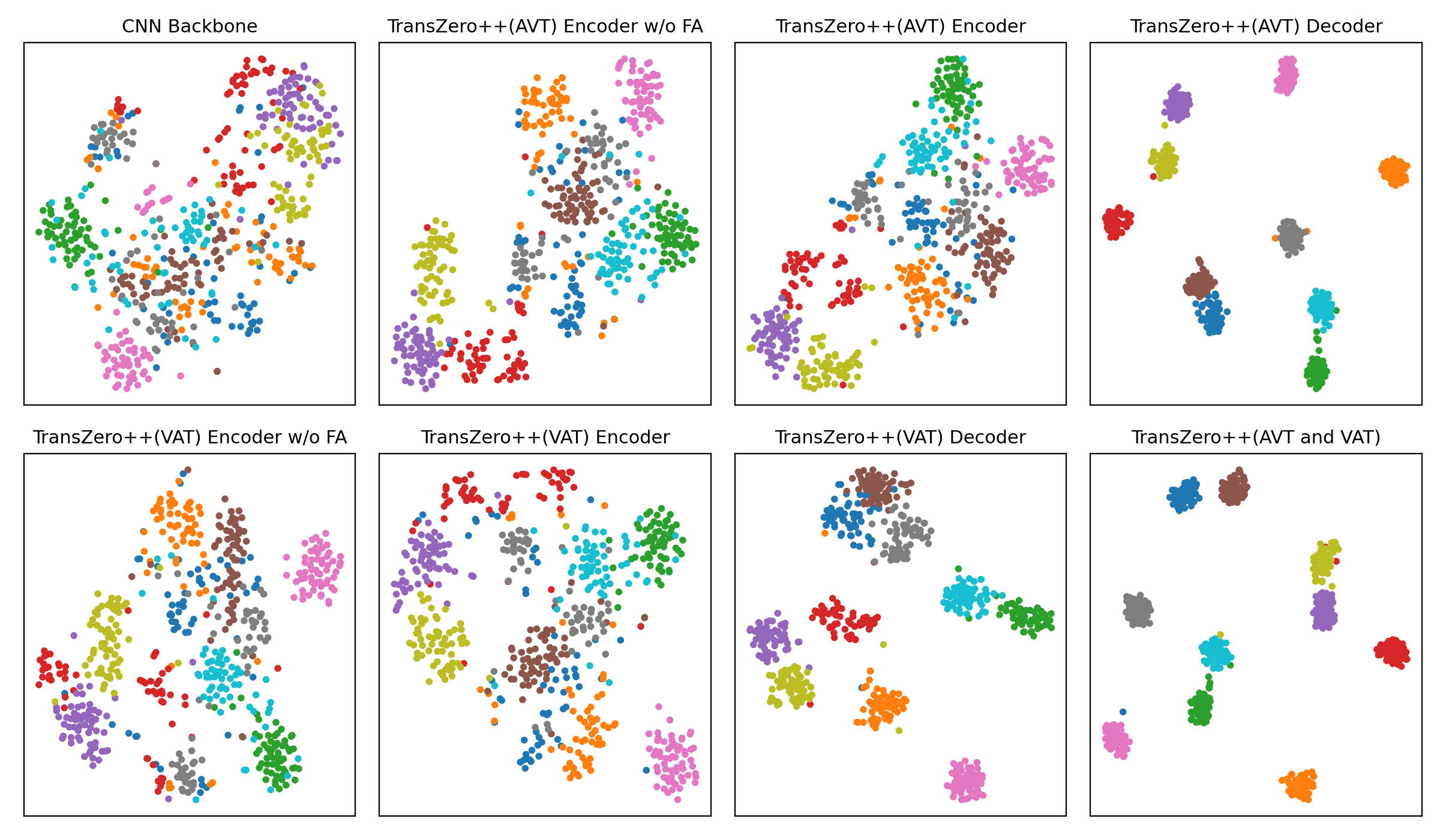
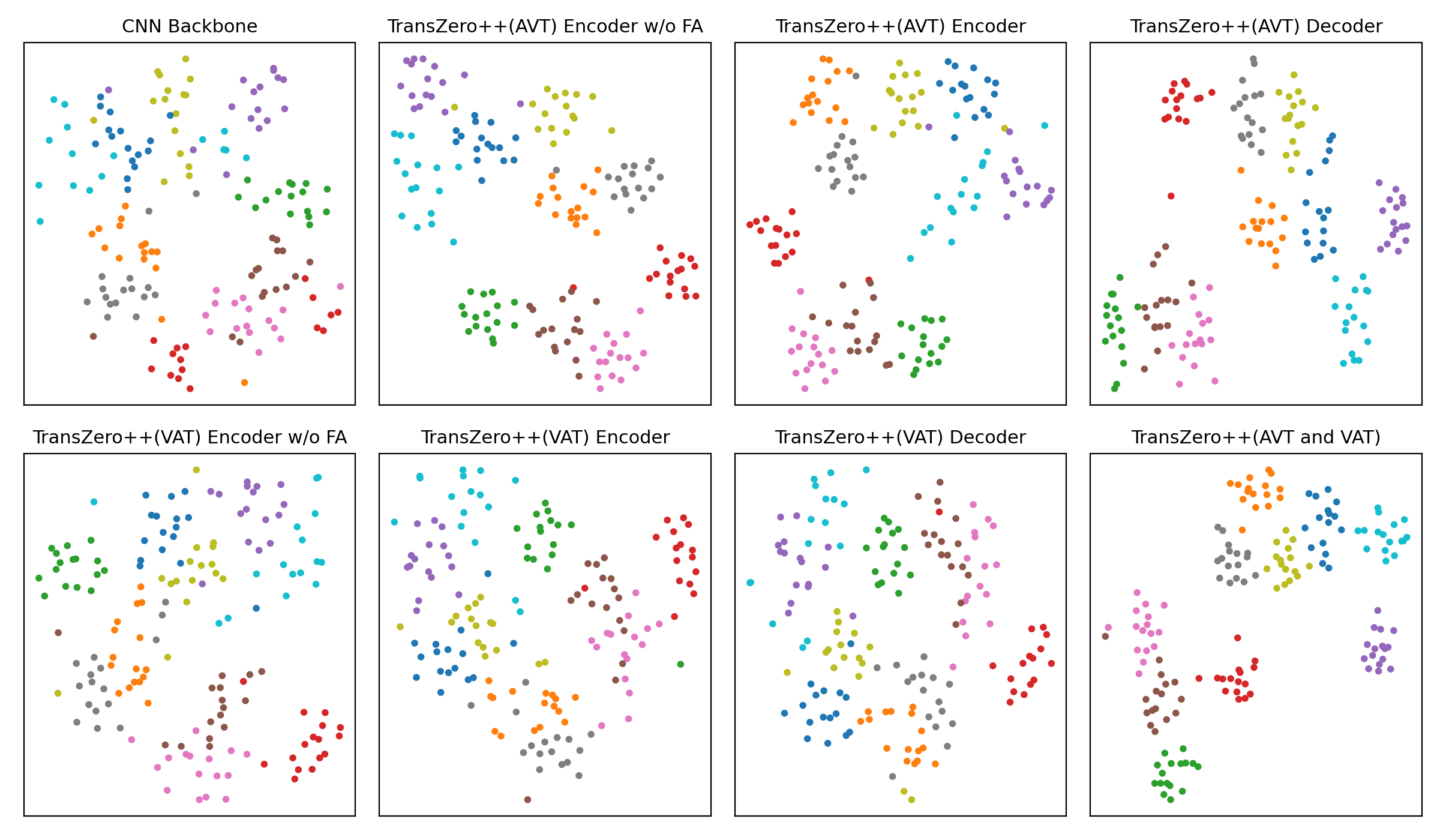
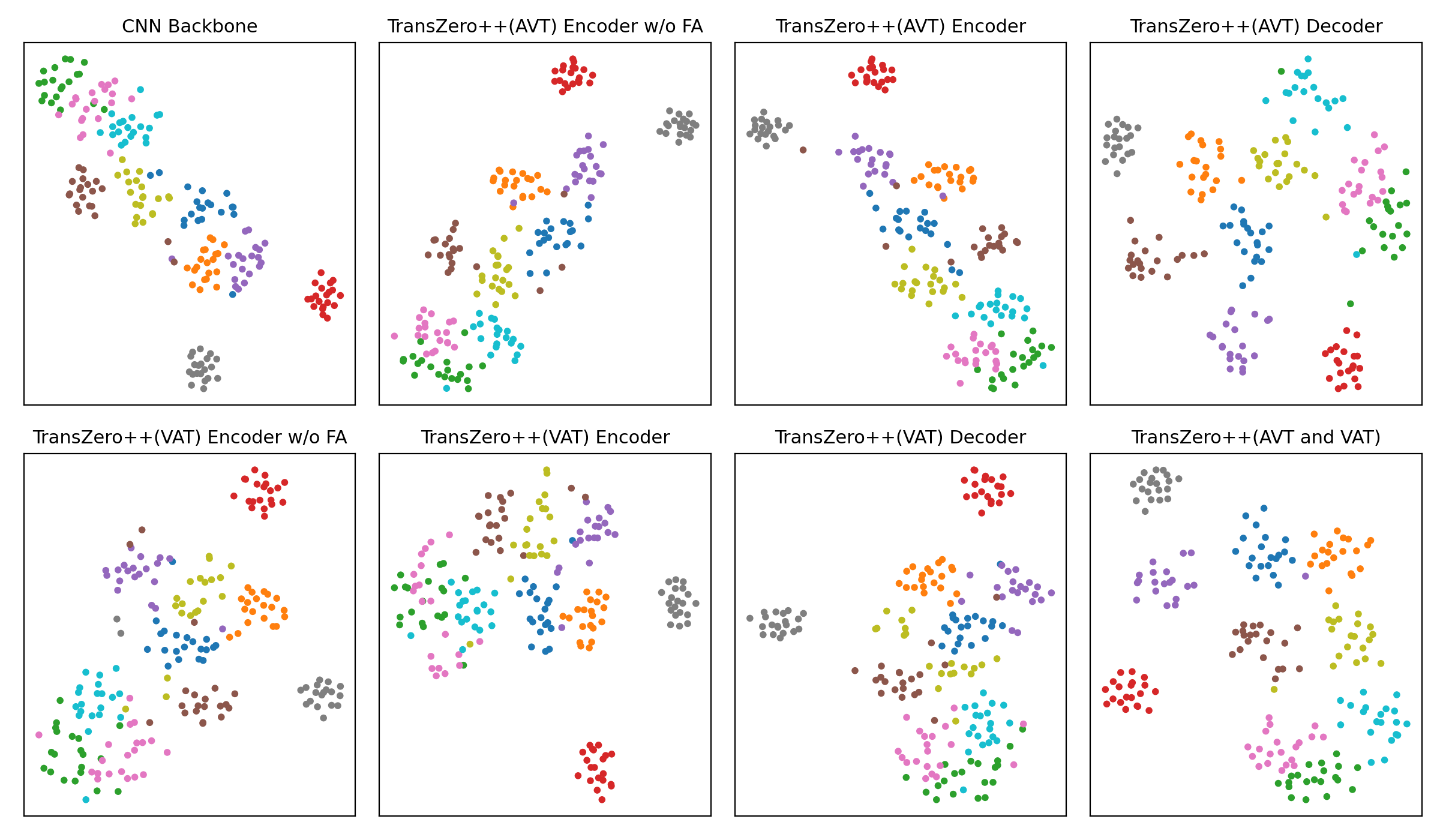
t-SNE visualizations of visual features for (a) CUB, (b) SUN and (c) AWA2, learned by the CNN backbone, TransZero++(AVT) encoder w/o FA, TransZero++(AVT) encoder, TransZero++(AVT) decoder, TransZero++(VAT) encoder w/o FA, TransZero++(VAT) encoder, TransZero++(VAT) decoder and TransZero++(VAT and VAT). The 10 colors denote 10 different seen/unseen classes randomly selected from these datasets. Results show that our various model components in TransZero++ learn the discriminative visual feature representations, while CNN backbone (e.g., ResNet101) failed. For each group, the first two rows are the visualizations of visual feature on seen classes, and the other two rows are on unseen classes.
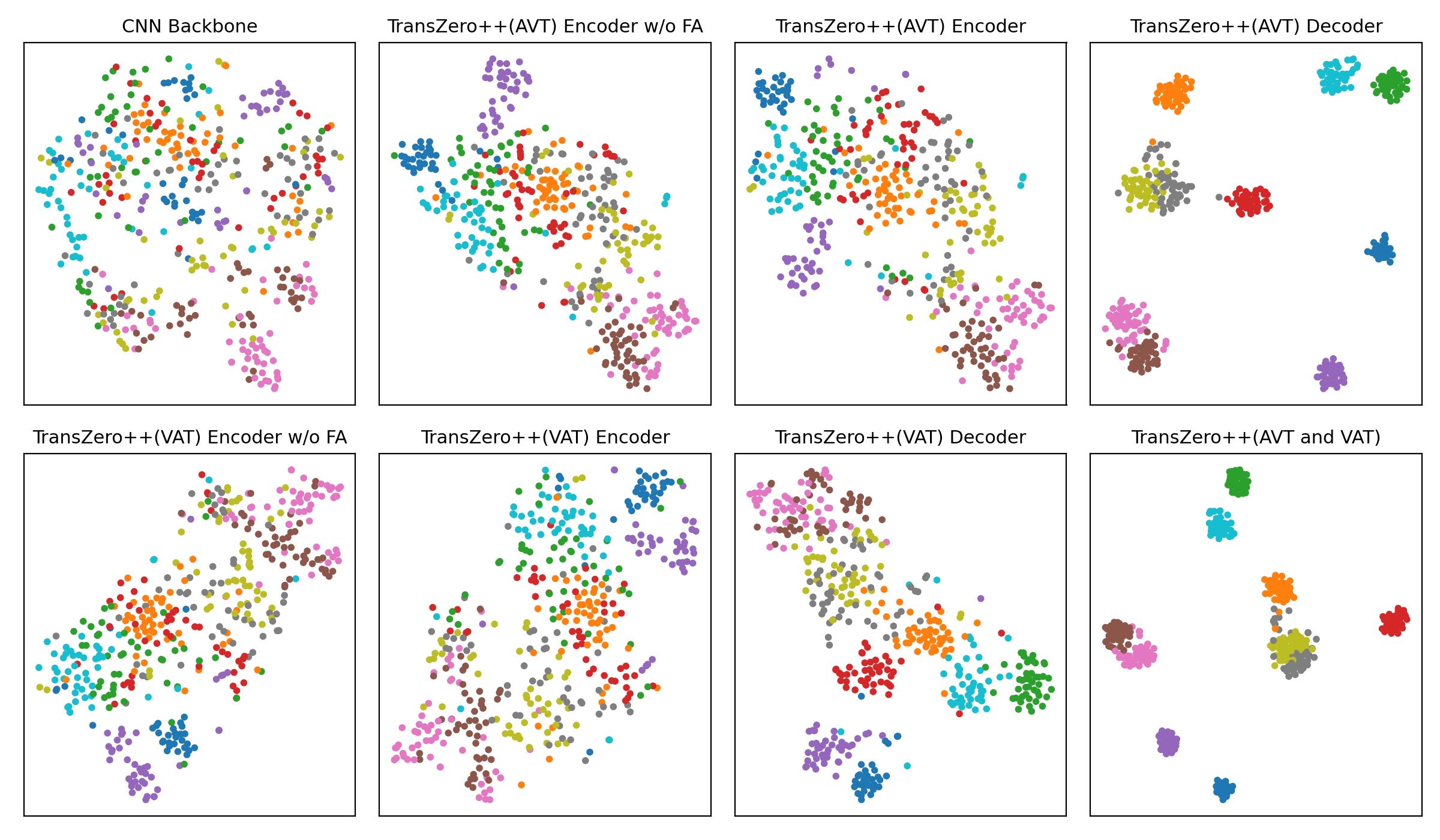
(a) CUB
(b) SUN
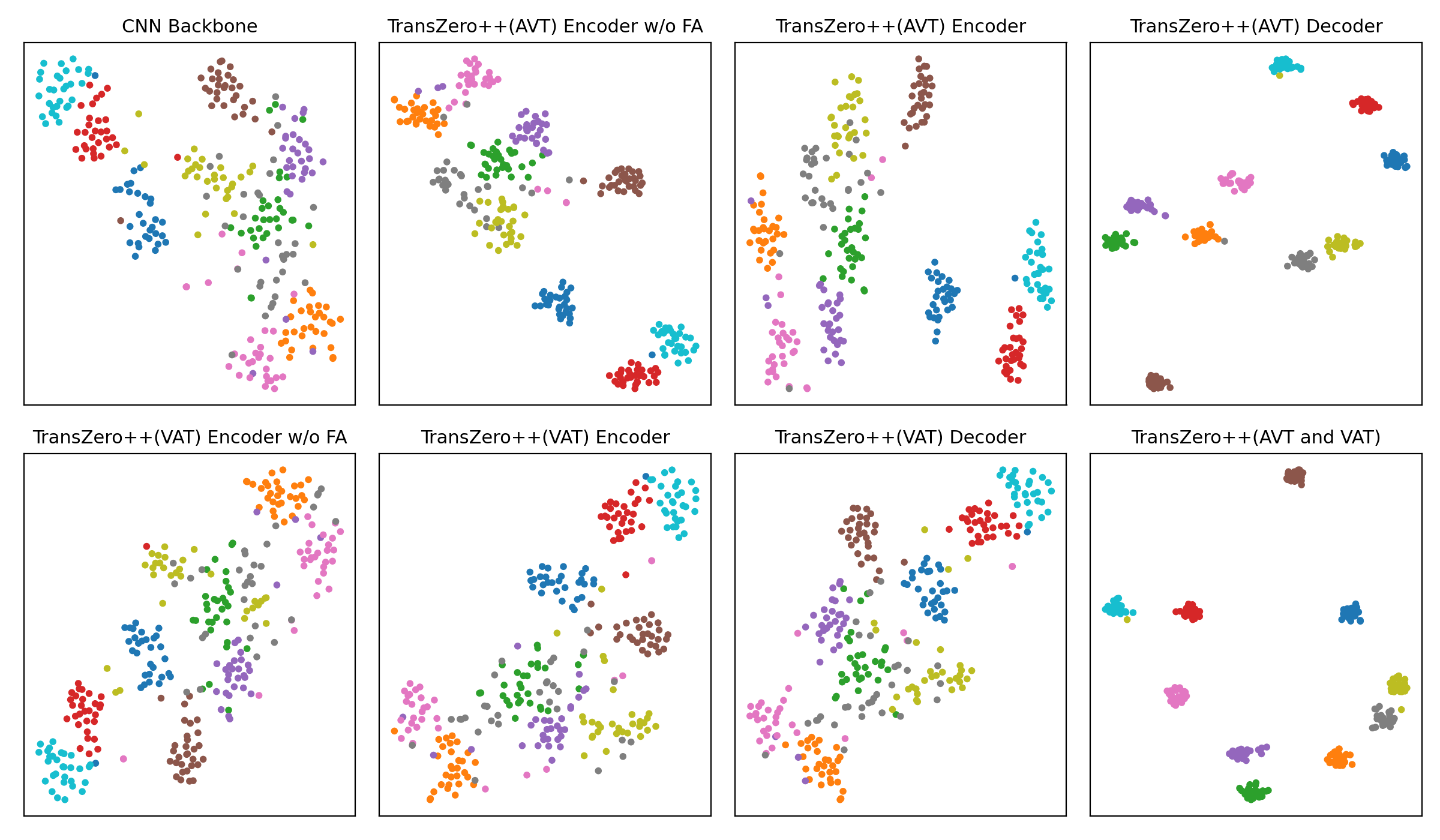

(c) AWA2
Experiment 3: Attention Maps
Visualization of top-10 attention maps for the AREN [2](top), TransZero [3] (middle) and our TransZero++ (bottom) in each group. Results show that TransZero localizes some important object attributes with low confident scores for representing region features, while AREN is failed. Furthermore, our TransZero++ discovers more valuable attributes that exist in the corresponding image with high confident scores compared to TransZero.



















































Acknowledgement
This work is partially supported by NSFC~(61772220,62006244), Special projects for technological innovation in Hubei Province~(2018ACA135), Key R\&D Plan of Hubei Province~(2020BAB027) and 2020-2022 Young Elite Scientist Sponsorship Program from China Association for Science and Technology YESS20200140.
Reference
[1] Yongqin Xian et al. "Zero-Shot Learning: A Comprehensive Evaluation of the Good, the Bad and the Ugly." In TPAMI, 2019.
[2] Guo-Sen Xie et al. "Attentive region embedding network for zero-shot learning." In CVPR), 2019.
[3] Shiming Chen et al. "Transzero: Attribute-guided transformer for zero-shot learning." In AAAI, 2022.
[4] Wenjia Xu et al. "Attribute Prototype Network for Zero-Shot Learning." In NeurIPS, 2020.